Since Hubot ships with a Redis Brain by default, I decided to use this as an opportunity to learn some Redis. While reading through Redis documentation, I came across Redis Mass Insertion, which sparked an odd curiosity (twinkle twinkle). The main crux of Redis Mass Insertion is a recommendation to write large data sets to a Redis instance using the Redis protocol with redis-cli --pipe rather than pushing data through a Redis client. The benefits are maximized throughput, better assurance of data consistency, and a nice validation message:
All data transferred. Waiting for the last reply...
Last reply received from server.
errors: 0, replies: 1000
The Redis Mass Insertion documentation includes a couple of short code snippets for generating test data and example commands for pushing data to Redis. From these snippets, I cobbled together a ruby script to generate an arbitrary number of K/V pairs to STDOUT:
#!/usr/bin/ruby
def int_check(val)
pass = Integer(val) rescue nil
if pass
val.to_i
else
STDERR.puts "Argument must be an integer."
exit
end
end
def gen_redis_proto(*cmd)
proto = ""
proto << "*"+cmd.length.to_s+"\r\n"
cmd.each{|arg|
proto << "$"+arg.to_s.bytesize.to_s+"\r\n"
proto << arg.to_s+"\r\n"
}
proto
end
def generate_data(val)
(0...val).each do |n|
STDOUT.write(gen_redis_proto("SET", "Key#{n}", "Value#{n}"))
end
end
generate_data(int_check(ARGV[0]))
The above script can be called as, ruby redis-pipe.rb 10000000 >> ./proto.txt to generate a file containing ten million key:value pairs.
From here I figured it might be fun to do a few benchmarks of redis-cli --pipe versus netcat HOST PORT, as well as protocol versus flat commands. I created a bash one-liner to generate the same data set from above as a flat list of Redis SET commands without the extra protocol markup:
i=0 ; while [[ ${i} -lt 10000000 ]] ; do echo " SET Key${i} Value${i}" ; i=$((i + 1)) ; done >> flat.txt
Here’s how the resulting files look:
$ du -a *.txt
274M flat.txt
464M proto.txt
$ head -7 proto.txt
*3
$3
SET
$4
Key0
$6
Value0
$ head -1 flat.txt
SET Key0 Value0
With data in hand, we just need a Redis instance to test against. I set up an Automated Build through Docker Hub with the current latest Redis version. I then deployed this container locally (OSX) via boot2docker: docker pull nhoag/redis && docker run --name redis -p 6379 -d nhoag/redis. Next I installed Redis locally with brew install redis to facilitate accessing the Redis container.
As a small test, we can connect to the container and SET and GET. But first we need the connection specs for the Redis container:
$ docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
ca48d4ff024e nhoag/redis:latest "redis-server /etc/r 2 seconds ago Up 1 seconds 0.0.0.0:49156->6379/tcp redis
$ boot2docker ip
192.3.4.5
Using the above information, we can connect with Redis as follows:
redis-cli -h 192.3.4.5 -p 49156
192.3.4.5:49156> SET a b
OK
192.3.4.5:49156> GET a
"b"
192.3.4.5:49156> FLUSHDB
OK
192.3.4.5:49156>
It works! On to mass inserts. As you can see above, I opted to pre-generate data to standardize the insertion process. This means we can run inserts as follows:
# Redis Protocol
$ cat proto.txt | redis-cli --pipe -h 192.3.4.5 -p 49156 > /dev/null
$ cat proto.txt | nc 192.3.4.5 49156 > /dev/null
$ cat proto.txt | socat - TCP:192.3.4.5:49156 > /dev/null
# Flat Commands
$ cat flat.txt | redis-cli --pipe -h 192.3.4.5 -p 49156 > /dev/null
$ cat flat.txt | nc 192.3.4.5 49156 > /dev/null
$ cat flat.txt | socat - TCP:192.3.4.5:49156 > /dev/null
Rinse and repeat after each iteration:
redis-cli -h 192.3.4.5 -p 49156DBSIZE- should be 10,000,000FLUSHDB
I introduced socat into the equation because my version of netcat doesn’t auto-recognize EOF. Some versions of netcat have -c or-q0, but not mine :( This means netcat will hang after the data has been fully processed until it’s manually told to stop. socat will automatically hang up on EOF by default, which is attractive as it allows simple benchmarking with time. But notice I haven’t included any time statistics. As you’ll see, I found a better alternative to time, and then kept the socat data since it was already in the mix.
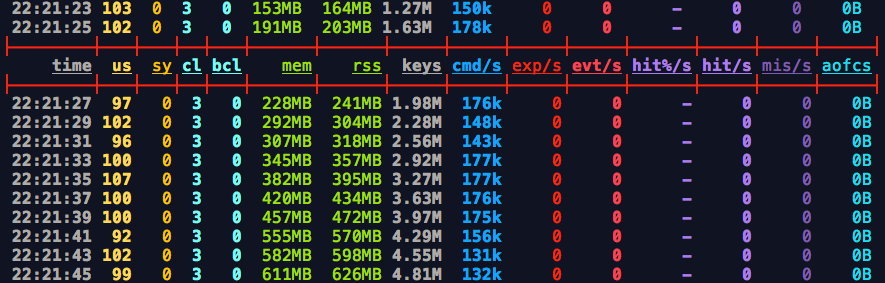
There is a very fun project for monitoring Redis called redis-stat. Using redis-stat --server=8282 192.3.4.5:49156 1, we get updates every second from the command line as well as in the browser at localhost:8282.
redis-stat command line
redis-stat browser
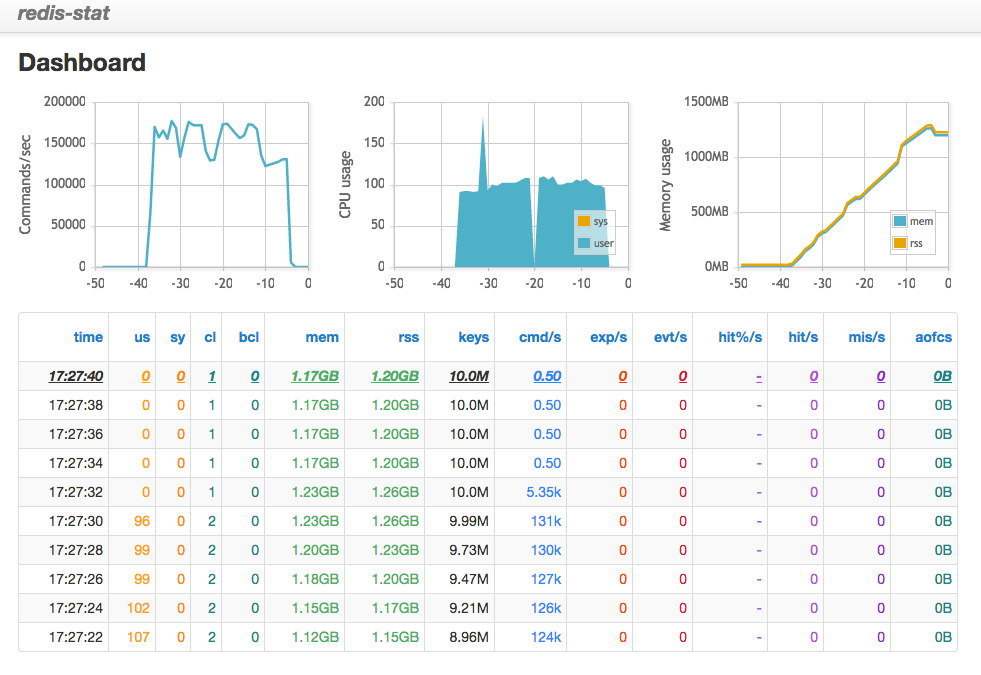
When Commands per Second and CPU Usage drop, and when Memory Usage levels off, we know it’s safe to shut down netcat. In the command line output we also get a rich dataset about how the insert performed that can be further parsed and analyzed. And the browser display provides a nice high-level overview.
In addition to redis-stat, I set up an ssh session running htop for an added lens into performance. This turned out to be very helpful in cases where the VM would unexpectedly hit capacity and start swapping, queuing, and backgrounding tasks. This didn’t happen often, but caused a massive slowdown for inserts.
The below data is from “clean” runs where the above-mentioned tipping point did not occur. Of course it would be better to run these inserts hundreds of times and aggregate the results. The data presented below is a semi-curated set of what seem to be typical responses for each insert method.
To generate the below data, I started with the raw redis-stat cli output. I parsed all of the rows that show insert activity, and then removed the first and last rows since these were typically inconsistent with the rest of the data set. Here is an example of generating an average for inserts per millisecond from a prepared data-set:
$ cat stats.txt \
| tail -n +2 \ # Remove the first line
| sed '$d' \ # Remove the last line
| awk '{print $9}' \ # Print the cmd/s column
| tr -d k \ # Remove the 'k'
| awk '{ sum += $1 } END { if (NR > 0) print sum / NR }'
161.148
161.148 * 1000 inserts * 1/1000s = 161 inserts/ms
Redis Protocol
| Command | - Time (s) | - Agg. Inserts/ms | - Avg. Inserts/ms |
|---|---|---|---|
| netcat | 63 | 159 | 161 |
| redis-cli | 57 | 175 | 169 |
| socat | 62 | 161 | 160 |
Flat Redis Commands
| Command | - Time (s) | - Agg. Inserts/ms | - Avg. Inserts/ms |
|---|---|---|---|
| netcat | 60 | 167 | 161 |
| redis-cli | 66 | 152 | 147 |
| socat | 66 | 152 | 148 |
redis-cli --pipewith the Redis protocol shows a slight performance edgenetcatwas the runner up in flat format and the Redis protocol was only slightly slowersocatwas comparable tonetcatwith the Redis protocolsocatandredis-cli --pipewithout Redis protocol were slower
TLDR: Use redis-cli --pipe with the Redis protocol for mass inserts and save on the order of 10+ minutes per billion K/V pairs ;)